

For over a year, every other Friday, I tweet about pushing code to production. It’s become a bit of a meme.
it's Friday 6pm, time to deploy to prod
— Boris Tane (@boristane) January 20, 2023
Unsurprisingly, quite a few people agree with me. Setting up CI/CD is relatively easy and affordable, and observability is not fringe anymore. There’s nothing special about Friday that should change your deployment behaviour.
But quite a few responses are from those who think I’m a lunatic for deploying code to production on a Friday at 6pm. They believe it’s an unnecessary risk and should be avoided at all costs.
You’re free to have Friday deployment freezes, but it is not helping your team, it’s actually hurting your team. It’s a band-aid on a more systemic problem: you have no confidence in your deployments and you are not willing to invest in fixing this problem.
When faced with this reality, what I usually get is a barrage of reasons to justify Friday deployment freezes. In this post I want to compile some of those reasons and debunk them individually.
Common reasons for not deploying on Fridays
I want a peaceful weekend
I hear it all the time. If you deploy on Friday at 6pm, you run the risk of being up all weekend fixing the mess the deployment might lead to. Your team runs the risk of staying up late fixing a bug that was unnecessary to deploy on Friday.
First of all, if one bad deployment leads to hours of bug-fixing, the problem is not just Friday deployment, it’s all deployments. This could happen on Tuesday at 6pm too. Are we going to have deployment freezes every day of the week after 2pm? Fair, it could happen at 10am on Wednesday too. Are we going to prevent deployments after 8:30am?
Friday deployment freezes actually hurt work-life balance believe it or not. It’s not because you don’t deploy on Fridays that you don’t get paged at 1am on a Wednesday night. If you don’t have the tools and processes to quickly identify the issue and roll back or roll forward quickly, you’re up for an entire night of firefighting.
Face reality, invest in your tooling and processes and deploy whenever you want. There’s nothing special about Fridays.
It’s fine for startups to YOLO to prod, but larger companies can’t
Yes, I work at a startup. Yes, we’re just a few engineers.
But, Amazon deploys every 11.6 seconds (in 2011). I highly doubt they achieve this deployment frequency with Friday deployment freezes.
Yes, outages at large organisations cost more than outages at small startups. But, infrequent deployments exponentially increase the likelihood of massive outages. Everything fails, all the time. And outages do not discriminate between enterprise and startups. You should focus your efforts on understanding and recovering from failure rather than preventing failure. The day things inevitably fail, you’re up for a lot of fun.

I want to deploy when the entire team is available
This is a fair point. If you deploy on Friday at 6pm, most of your team is already off for the weekend. And if things go south with a deployment, you want support to help diagnose potential unforeseen dependencies.
And that’s the problem.
This is a symptom of a much bigger problem, as a developer, you have no idea of the downstream impact of your code changes, and you have no way of identifying those in real time. Knowledge in your organisation is siloed and whoever is on call usually is not having a good time.
Fix that.
How? with observability. It doesn’t matter how you do it, but you should focus one or more engineering cycles on enabling everyone on your team to independently diagnose and fix issues caused by code changes, whether they wrote the code in the first place or not.
It’s not about Friday, it’s about fear
The common thread among Friday deployment freezes is fear. Fear of breaking production when you were looking forward to a weekend. Fear of breaking production and costing your company a lot of $$$. Fear of being left alone to debug something without understanding what you’re doing.
There’s nothing more detrimental to your team's well-being and company bottom line than fear of deployments.
Science says you should deploy all day, every day
I didn’t make this up, it’s literally science. The more frequently you deploy, the lower your error rates. Improving one metric feeds into the other. And it’s intuitive.
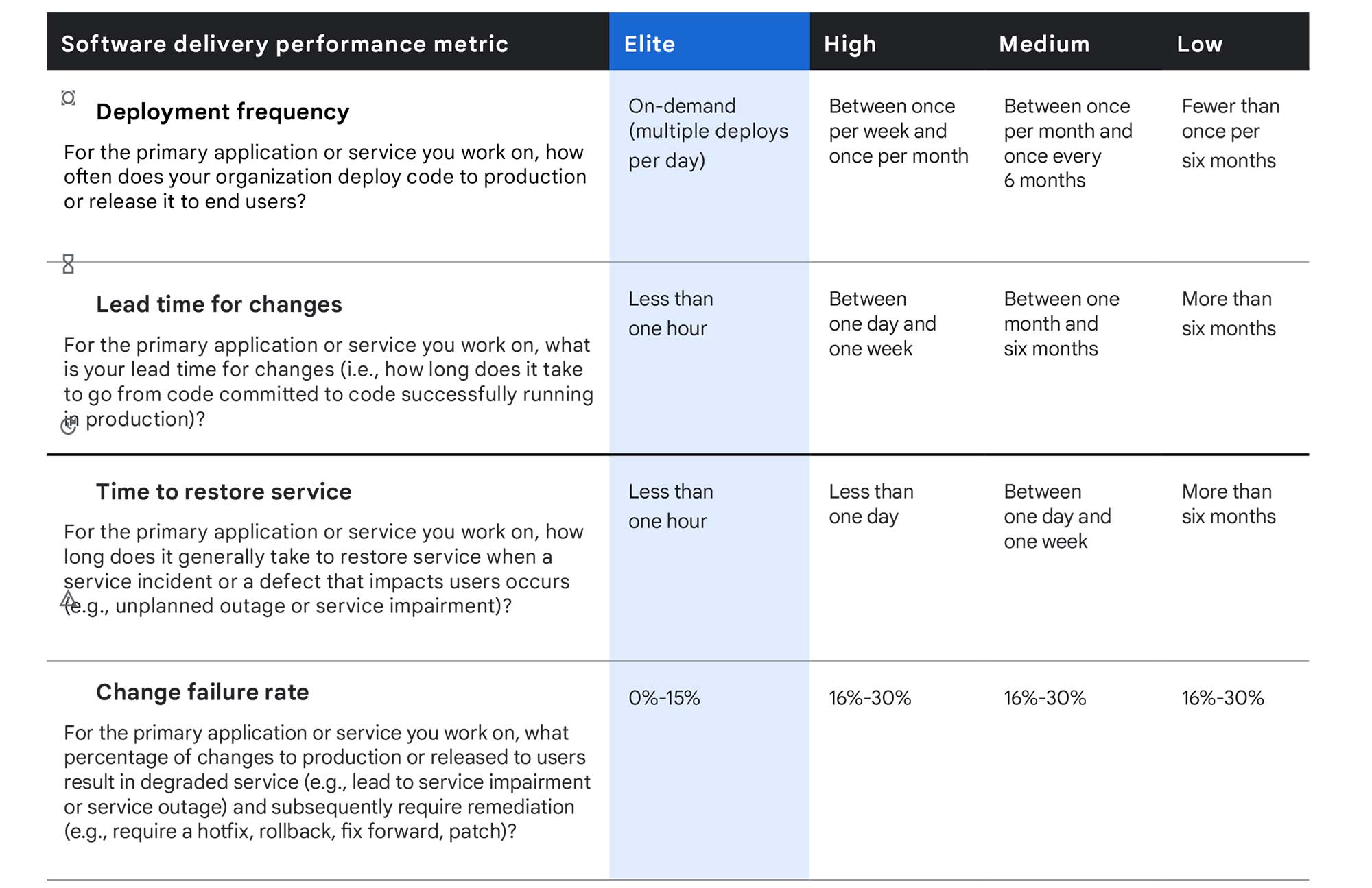
If you deploy frequently, you most likely deploy smaller changes, and smaller changes are less likely to result in outages than a batch of unrelated changes that might have unintentional dependencies.
And what’s the easiest and fastest way to create batched deployments? Freeze Friday deployments such that all the work completed on Friday gets deployed on Monday.
Any issue that happens on Monday arises over 48 hours after the code was written, context is lost, it’s muddied with other changes, and nobody actually owns the deployment. It’s going to take significantly longer to identify the issue and fix it. The same engineers we wanted to protect from fixing issues on Friday are now having a much harder time fixing the same issues on Monday.

Stop throwing code over the fence and hoping it works
One of the reasons you don’t want to deploy on Friday is you don’t know what your code does and how it interacts with other systems, but why? Because you don’t have the tools to know this in real time.
If you deploy code and bite your nails looking at dashboards and tailing your logs hoping nothing is broken, you should do something about it. It happens on Fridays and on Mondays, Tuesdays, Wednesdays, and Thursdays. The anxiety of broken deployments is plaguing your team every single day of the week. You should fix that.
Adopt healthy habits
A subset of people misunderstands my stance for Friday deployments as my advocating for cowboys deploying at 4:59pm and running out the door. Absolutely not. Don’t be reckless.
If your only tooling is a set of dashboards about CPU and memory usage, and a set of bash scripts to run from a virtual machine, please apply some judgement before deploying.
If you have more advanced tooling, deploy single commits, decouple deployments from releases, and actually verify that your code changes are working as expected, right after you deploy. You’re responsible for the code changes you make to production.
What you should start doing today
If you are not able to confidently deploy on Fridays, there are a few steps you can take to get you there. You will be happier, your team will be happier and you’ll have calmer weekends and evenings:
- Invest in automating your deployments. If it currently takes 14 manual steps to get code from a developer’s workstation to production, you need to invest in automating this.
- Deploy small changes, don’t batch multiple things into a single deployment. It’s been said multiple times, and I understand you; it’s easier to batch changes and make one big deployment if every deployment takes 1 hour. Invest in reducing this time.
- Every developer should own their deployments. When you push code to production, you’re responsible for verifying that deployment was successful, that the code works as expected, and that it doesn’t adversely impact other systems.
- Instrument your code. The only way to reliably know if a deployment works as expected is with telemetry data. Provide observability tooling that makes instrumenting and exploring data easy.
Friday deployment freezes are the symptoms of deeper engineering culture issues. With the steps above, you will start to move the needle and soon you’ll be able to ship code to production 10’s of times every Friday and join the Friday deployments crew.